



EC system is good, because it makes you to explore.
At least, it made me to explore. By exploring, I have come across with too many "good" blogs. Now I can tell at least a dozen of nice sites/blogs, which I had never come across under other system of exploration. The other systems such as BlogRush and GoodBlogs simply lagged (?) because there was no such motivation for bloggers.
I should thank 'em for that.
Everything was alright , if not perfect , suddenly there came the "new law". Which is based upon 2^X law.
Well, there are good side and bad side. (see the links at the end)
I think the pricing should depend on factors such as: number of drops received/unique visitors, ads in que... and one more important factor may be PR or popularity index.
We should always be thinking of new blogs or new members of ec community. Because Blogging is also about community. There should be fair chances for them so that they can still receive enough attention.
Under the news system, since the price jumps up immediately.
No one will be willing to spending a lot of hard earned ec credits on some-where with only few visitor per day.
Simply put : 2^X is not a better idea!
Think of some idea by which new/hobby bloggers (like me) do not get crushed and yet the spam sites get punished!
Let's try to be more creative. Make up new formula which grows very slowly (like x^2) in the beginning, and becomes exponential at some point and then becomes linear.
I do love the no-cap feature.
Thanks for reading!
I liked these posts:
http://turnipofpower.com/2008/04/13/entrecard-advertising-value-strategy/
http://ageeksjourney.com/traffic/entrecard-a-new-start-or-end/
http://flimjo.com/wp-trackback.php?p=109
http://www.quickonlinetips.com/archives/2008/04/entrecard-changes-pricing-algorithm-card-dropping-game-stops/trackback/
Monday, April 14, 2008
Monday, March 24, 2008
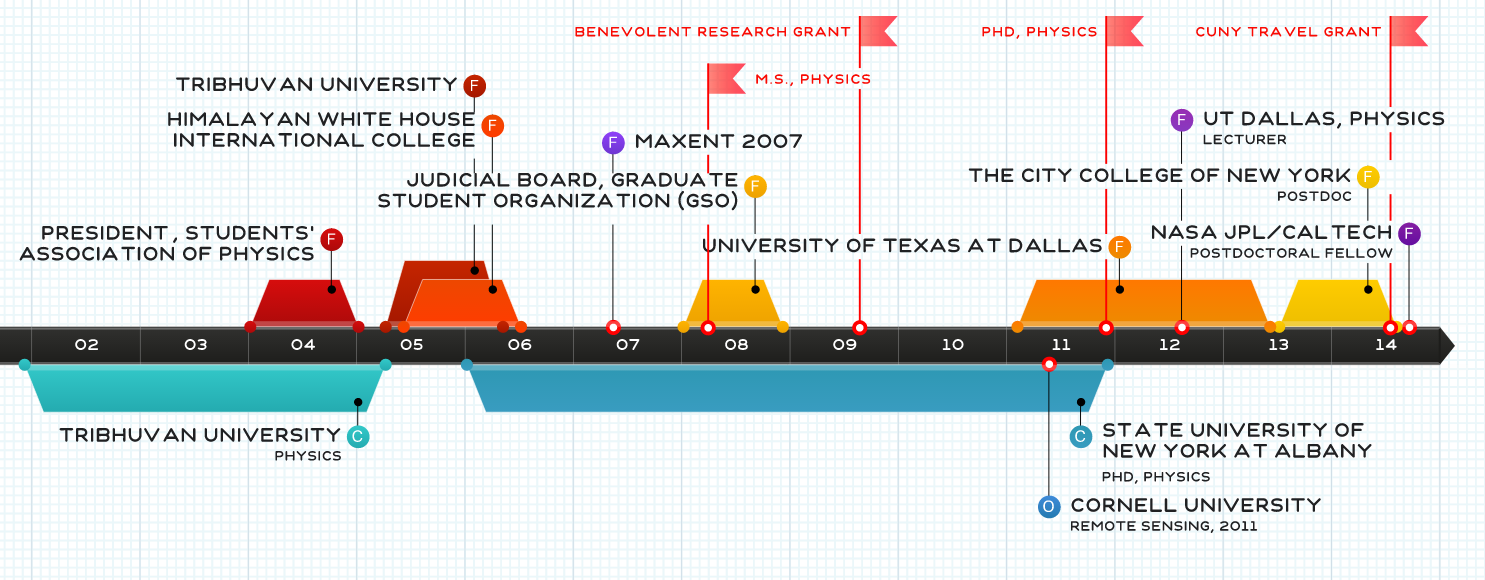
Nepali Physicists in 2008 APS (March Meeting)
A list of Nepali physicists participating in the 2008 APS March meeting held at Morial Convention Center, New Orleans,
Louisiana,
USA.
-------------------------------
(1) Dr. Bed Poudel - Boston, MA
(2) Mr. Trilochan Poudel - Boston College, MA
(3) Mr. Shankar Kunwar - Boston College, MA
(4) Mr. Sushil Joshi - Boston College, MA
(5) Mr. Rajendra Dahal - Kansas State University, KS
(6) Mr. Bed Nidhi Pantha - Kansas State University, KS
(7) Mr. Parashu Ram Kharel - Wayne State University
(8) Mr. Rajesh Regmi - Wayne State University, MI
(9) Mr. Arjun Pathak - Southern Illinois University,IL
(10) Mr. Rakesh Shah - Southern Illinois University, IL
(11) Mr. Krishna Sigdel - Worcester Polytechnic Institute, MA
(12) Mr. Rudra Kafle - Worcester Polytechnic Institute, MA
(13) Mr. Pashupati Dhakal - Boston College, MA
(14) Mr. Sanjaya Adhikari, Towson University, MD
(15) Mr. Khim Karki, Towson University, MD
(16) Mr. Pushkal Thapa - Wayne State University
(17) Mr. Ashok Sedhain - Kansas State University
(18) Dr. Prem Chapagain - Florida International University, FL
(19) Dr. Tara Dhakal - University of Southern Florida, FL
(20) Mr. Hari Dahal - Boston College, MA
(21) Dr. Lekh Nath Bhusal - NREL , Golden , CO
(22) Mr. Laxman Mainali - SUNY at Albany, NY
(23) Mr. Indra Dev Sahu - SUNY at Albany , NY
(24) Mr. Sanjay Prabhakar - SUNY at Albany, NY
(25) Mr. Amar Bahadur Karki - Louisiana State University, LA
(26) Mr. Krishna Neupane - University of Miami, FL
(27) Mr. Suman Khatiwada, Morgan State University, MD
(28) Mr. Krishna Neupane - Kent State University, OH
(29) Mr. Shyam Raj Badu - SUNY at Albany, NY
(30) Mr. Parashu Ram Gyawali - Kent State University, OH
(31) Mr. Madhab Neupane - Boston College, MA
(32) Mr. Pushkar Dahal - Kenyon College, OH
(33) Mr. Suman Khatiwada - Morgan State University, MD
(34) Dr. Bijaya Bahadur Karki - Louisiana State University, LA
(35) Mr. Tula Poudel - Case Western Reserve University, OH
(36) Mr. Prem Thapa - Oklahoma State University, OK
(37) Dr. Mukesh Dhamala - Georgia State University, GA
------------------------------------------
Updated by Rudra Kafle
At 7:47 A.M. Central Time
Friday, March 14 , 2008
Quoted from the Google Group of Nepal Physical Society
Louisiana,
USA.
-------------------------------
(1) Dr. Bed Poudel - Boston, MA
(2) Mr. Trilochan Poudel - Boston College, MA
(3) Mr. Shankar Kunwar - Boston College, MA
(4) Mr. Sushil Joshi - Boston College, MA
(5) Mr. Rajendra Dahal - Kansas State University, KS
(6) Mr. Bed Nidhi Pantha - Kansas State University, KS
(7) Mr. Parashu Ram Kharel - Wayne State University
(8) Mr. Rajesh Regmi - Wayne State University, MI
(9) Mr. Arjun Pathak - Southern Illinois University,IL
(10) Mr. Rakesh Shah - Southern Illinois University, IL
(11) Mr. Krishna Sigdel - Worcester Polytechnic Institute, MA
(12) Mr. Rudra Kafle - Worcester Polytechnic Institute, MA
(13) Mr. Pashupati Dhakal - Boston College, MA
(14) Mr. Sanjaya Adhikari, Towson University, MD
(15) Mr. Khim Karki, Towson University, MD
(16) Mr. Pushkal Thapa - Wayne State University
(17) Mr. Ashok Sedhain - Kansas State University
(18) Dr. Prem Chapagain - Florida International University, FL
(19) Dr. Tara Dhakal - University of Southern Florida, FL
(20) Mr. Hari Dahal - Boston College, MA
(21) Dr. Lekh Nath Bhusal - NREL , Golden , CO
(22) Mr. Laxman Mainali - SUNY at Albany, NY
(23) Mr. Indra Dev Sahu - SUNY at Albany , NY
(24) Mr. Sanjay Prabhakar - SUNY at Albany, NY
(25) Mr. Amar Bahadur Karki - Louisiana State University, LA
(26) Mr. Krishna Neupane - University of Miami, FL
(27) Mr. Suman Khatiwada, Morgan State University, MD
(28) Mr. Krishna Neupane - Kent State University, OH
(29) Mr. Shyam Raj Badu - SUNY at Albany, NY
(30) Mr. Parashu Ram Gyawali - Kent State University, OH
(31) Mr. Madhab Neupane - Boston College, MA
(32) Mr. Pushkar Dahal - Kenyon College, OH
(33) Mr. Suman Khatiwada - Morgan State University, MD
(34) Dr. Bijaya Bahadur Karki - Louisiana State University, LA
(35) Mr. Tula Poudel - Case Western Reserve University, OH
(36) Mr. Prem Thapa - Oklahoma State University, OK
(37) Dr. Mukesh Dhamala - Georgia State University, GA
------------------------------------------
Updated by Rudra Kafle
At 7:47 A.M. Central Time
Friday, March 14 , 2008
Quoted from the Google Group of Nepal Physical Society
Wednesday, February 27, 2008
Gmail Captcha Broken by Spammers!
CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) challenge-response systems, which prevents automatic creation of accounts/ or automatic posting of messages. It involves a user (human) to correctly identify letters/digits in the form of an image. These are designed to ensure requests are made by a human rather than an automated program/software. The technique has been used to defeat automatic sign-ups to email accounts by services including Yahoo! Mail and Gmail, and has been the nail-biting challenges for hackers.
Recently, I got the news that Spammers have broken the system at Gmail. Recently the success of cracking the Windows Live captcha used by Hotmail was also reported. If they keep being successful at it, then we will be having a huge percentage rise in spam. The main worries are being the reason that nearly no spam blocker will identify and blacklist it as “spam”.
Internet security firm Websense reported bots have been created which are capable of signing up and creating random Gmail accounts for spamming purposes, defeating Captcha-based defences in the process.
Websense considers the latest Gmail Captcha hack to be the most sophisticated one it has seen to date. Live Mail Captcha breaking involved just one zombie host doing the entire job, the Gmail breaking process involves two hosts. One to try, and another to monitor the success. The two compromised hosts applies a slightly different technique to analyse Captcha.
They have reported that only one in every five Captcha-breaking attempts is successful. It seems to be low, but that's more if we consider millions of automated attacks.
Report:
http://www.websense.com/securitylabs/blog/blog.php?BlogID=174
CAPTCHA:
http://www.answers.com/captcha?cat=technology&gwp=13
Links:
http://www.codinghorror.com/blog/archives/001067.html
Wednesday, February 13, 2008
Bayesian Spam filtering
This is from the blog: Time!
http://ajabgajab.blogspot.com/2007/07/bayesian-spam-filtering.html
Imagine a situation: you are receiving more than hundred Emails. You have to read each of them and classify whether it is good or bad one, for your BOSS.






http://ajabgajab.blogspot.com/2007/07/bayesian-spam-filtering.html
Imagine a situation: you are receiving more than hundred Emails. You have to read each of them and classify whether it is good or bad one, for your BOSS.
Stressed? It seems like a stupid question because , now a days, it is not the real situation , right?
You see that there are two folders: Inbox and Bulk(spam). And one more called trash.
Life is so easy!
Eventually there are some, which make the way through.
How is that possible?
If you are receiving less spam, it is the boon of Bayesian Spam Filtering.
It works by learning.
Exactly like we would do, If we face the first condition,
We would start classifying the mails according to its contents and some key words provided by the boss. If confused, with some new situation, feel free to ask the boss. Sub-consciously we will be attributing the spam coefficient to each mail, and finally, to decide whether the Email is Spam or not.
Therefore there will be some training data (lets say) to begin with. Each time we classify the Email, we will become expert so as to classify whether the mail is spam or not. After gaining enough expertise, there are no spams for your BOSS to read (sounds ambitious) . He is also happy that he has to train less and less to classify the incoming mails, as you are gaining the expertise on the environment.
In contrast, you are smart enough, not to mark it spam just by only seeing some key-words used to mark spam. It is the overall mail that will affect your decision. Am I right?
Suppose you change the office, say from management to health. The nature of mails are very different. For example, the term “Pills” may not be spam anymore! While a very good proposal “invitation to join business partnership from africa” is likely to be a spam. If you mark it with the training gained in previous office, you are in trouble!
It would be advantageous for your boss to read all the Emails (including spams) himself than to loose a single (but important) mail.
The advantage of Bayesian spam filtering is that it gets customized with user and the coefficient of spamness differs from user to user.
Well, watch the situation from the eyes of a spammer! You will clearly see the difficulties to spam the mail box. You would be forced to think!
HOW TO SPAM? Some people just can not sleep without spamming.
Because, even if you are able to get through, the way you found will work only once, there is no next chance through the same door. If marked spam (training), there will be no way to that trick for the next time .
Learning makes it possible.
Useful readings:
I am highly inspired by:
http://www.paulgraham.com/spam.html
and listening to Prof. Kevin Knuth, Prof. Carlos Rodriguez, Adom Giffin and Roger Pink.
Recommended texts:
Sunday, February 3, 2008
Wikipedia: A reliable source of information?
Do you think that wikipedia is the reliable source of information?
Yes (74%)
No(23%)
Don't care(2%)
Total vote: 47.
This is the result of the poll conducted in my blog: Time! (http://ajabgajab.blogspot.com)
The key question over here is what kind of information do we need? And what is the meaning of the reliability ?
Wikipedia is, of course, not the source of reliable news. Even some of the history chapters may have been biased.
I was reading some news on wikipedia that there had been two cases where the death of the peoples had been posted before they were actually killed. Similarly, when I was seeking the news on indian Idol, people would work hard to keep changing the names of the participant who have been voted out, I think they amused themselves by doing that.
When Reliability is the key question, I would wait and see.
However, when we do search, there are wikipedia results. For me I do peek into the results implied by the wikipedia link.
Answers.com has been nice place for me when I try to see definitive answers. And, most of the time I have been looking for some definitive results. There are of course Wikipedia results.
Yes (74%)
No(23%)
Don't care(2%)
Total vote: 47.
This is the result of the poll conducted in my blog: Time! (http://ajabgajab.blogspot.com)
The key question over here is what kind of information do we need? And what is the meaning of the reliability ?
Wikipedia is, of course, not the source of reliable news. Even some of the history chapters may have been biased.
I was reading some news on wikipedia that there had been two cases where the death of the peoples had been posted before they were actually killed. Similarly, when I was seeking the news on indian Idol, people would work hard to keep changing the names of the participant who have been voted out, I think they amused themselves by doing that.
When Reliability is the key question, I would wait and see.
However, when we do search, there are wikipedia results. For me I do peek into the results implied by the wikipedia link.
Answers.com has been nice place for me when I try to see definitive answers. And, most of the time I have been looking for some definitive results. There are of course Wikipedia results.